
Abstract:
This article traces the evolution and history of Artificial Intelligence from its theoretical beginnings to modern breakthroughs like deep learning, and more familiar versions such as large language models, manifested through technologies such as ChatGPT. By examining key developments, from the perception and backpropagation to transformers, this article highlights how machines have transitioned from rule-based logic to learning from data. It also underscores AI’s growing role in reshaping how problems are solved and how humans interact with technology.
Key Words:
Artificial Intelligence, Generative AI, Machine Learning, Deep Learning, Language Models, Transformers
The core idea behind this issue of Generations Journal is that Artificial Intelligence (AI) represents a shift in how we approach problem-solving. In the past, programmers had to understand a problem and manually design a solution. Now, with AI, one can feed a preliminary solution or sample data into an AI model, which then learns the underlying problem and eventually discovers and refines its methods to solve it. This has given rise to a new paradigm in which solutions emerge not from handcrafted rules but from learning patterns in data, and allows machines to tackle problems people may not fully understand.
A Primer on Context and Terminology
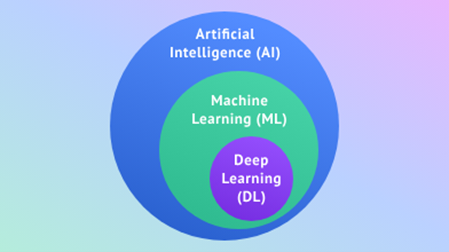
AI is a broad field focused on building machines that can mimic human intelligence, from understanding and reasoning to learning and interacting. One major approach in the AI field is Machine Learning (ML), where instead of explicitly programming a solution, we teach machines to learn from data. This is achieved using algorithms and techniques that enable models to identify patterns, draw inferences, and make decisions based on experience. Think of it as showing a computer thousands of examples until it begins to recognize patterns and improve its performance over time, without needing to be reprogrammed for each new task.
Early ML systems could play checkers or recognize simple shapes, showcasing computers’ ability to learn autonomously. Pioneers in ML paved the way for more advanced methods and complex neural networks. These early advances laid the groundwork for more sophisticated approaches, eventually leading to Deep Learning (DL), a more advanced subset of ML.
DL uses multilayered neural networks—inspired by how the human brain works—to solve complex problems. These deep networks excel at automatically finding subtle patterns in massive datasets, making them foundational to modern AI applications. Related fields within AI include Natural Language Processing (NLP), which helps machines understand and generate human language, and Computer Vision (CV), which enables machines to interpret and analyze the visual world. At the heart of many of these systems are Neural Networks—algorithms designed to detect and model relationships in data in ways that mimic the brain’s structure and function.
A Brief History of AI
The concept of machines that can think has intrigued humanity since ancient times. In Greek mythology, figures like Hephaestus and Daedalus were said to have created self-operating machines, such as Talos, a giant bronze automaton tasked with protecting Crete (Mayor, 2023). These myths reflect the long history of human fascination with artificial beings and intelligent machines.
In the early 20th century, researchers began exploring the human brain’s physiology to inspire machine intelligence. Earlier studies had shown that brain neurons function as electrical units, firing in all-or-nothing pulses—a principle known as the “all-or-none law” (Adrian, 1914). This binary-like signaling system was foundational to later brain function and computation theories. The principle was rigorously explored by Edgar Adrian, who would later win the Nobel Prize for his work in neurophysiology. His 1914 publication demonstrated that nerve cells transmit signals in uniform electrical spikes rather than in varying strengths, reinforcing the idea that the brain operates in a digital-like fashion (Adrian, 1914).
In the 1940s and early 1950s, researchers Warren McCulloch and Walter Pitts developed simple mathematical models of neurons, the basic building blocks of the brain. Their paper demonstrated that it was possible to model human brain activity mathematically through “all-or-none law” principles (McCulloch & Pitts, 1943).
‘This was the hope for building a machine that could think more like a human by combining many simple neurons into a more complex system.’
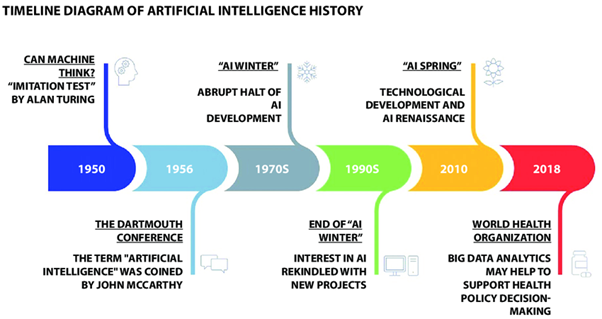
In 1950, Alan Turing wrote “Computing Machinery and Intelligence.” In that article, he asked the famous question—“Can machines think?”—and introduced the Turing Test as a way to see whether a machine could mimic human conversation (Turing, 1950). This was an early exploration of AI’s potential in the areas of human behavior and decision-making skills. Then, in 1958, Frank Rosenblatt built the perceptron, an early neural network (a type of AI model inspired by how the human brain processes information) that could learn to recognize simple patterns (Rosenblatt, 1958). These breakthroughs set the stage for the Dartmouth Conference in 1956, organized by John McCarthy and his colleagues, which is has come to symbolize the official birth of AI as a field (Peter, 2024).
However, not everything went smoothly. Early AI research split into two camps. One camp, called symbolic AI, focused on using logic and rules to make machines think like humans (Babar, 2024). The other camp worked on neural networks that tried to mimic our brains. Both approaches made huge promises, but they couldn’t deliver on all those expectations (Babar, 2024). This triggered the first AI winter in the mid-1970s, following James Lighthill’s report that highlighted critical shortcomings in AI systems, leading to a sharp decline in funding and enthusiasm for the field (Agar, 2020).
Backpropagation, invented in 1970 by Seppo Linnainmaa, was a game-changing breakthrough in how we train neural networks (Raghuvanshi, 2023). Backpropagation is like a feedback system: When a network makes a mistake, backpropagation tells each neuron exactly how much it contributed to the error. This lets the network adjust its “weights” (the strength of each connection) so it can improve over time, much like a student learning from corrections on a test.
With backpropagation, researchers could start stacking neurons in multiple layers, creating what we call deep neural networks. In theory, these layered networks could learn increasingly complex tasks, with each layer acting as a filter that gradually turns raw data into a higher-level understanding. This was the hope for building a machine that could think more like a human by combining many simple neurons into a more complex system.
However, even with this promising technique, the technology of the time wasn’t quite ready. The early neural networks, though exciting, still required a lot of manual tweaking and couldn’t handle many real-world problems. Expectations soared, but the models often underperformed because the hardware and training methods were too limited, causing the second AI winter (Babar, 2024).

In 2012, a powerful neural network called AlexNet (above see classified images from the AlexNet model in their initial study [Krizhevsky et al, 2012]), created by Alex Krizhevsky and colleagues (2012), made headlines by winning the ImageNet competition and cutting error rates in image recognition by a huge margin. This stride was made possible by using graphics processing units (GPUs), originally the same type used in computer gaming and video rendering to speed up the training process (Kang, 2024). Neural networks represent information in a format that GPUs are optimized to process, resulting in faster training (Kang, 2024). This breakthrough showed that with enough data and the right hardware, especially GPUs, neural networks could solve problems that once seemed computationally out of reach.
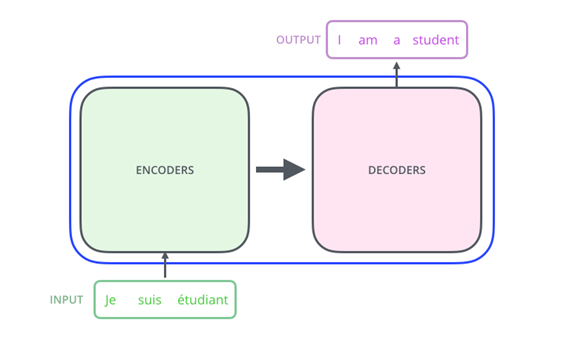
Above, an example of an implementation of RNNs and LSTMs is translation models (Alammar, n.d.).
At the same time, improvements in Recurrent Neural Networks (RNNs) helped computers handle sequential data, making them great for language tasks like translation and speech recognition (Stryker, n.d.).
In 2017, a new architecture called Transformers arrived with the famous “Attention Is All You Need” paper (Vaswani et al., 2017). Transformers revolutionized the way AI understands language by focusing on the relationships between words in a sentence without the limitations of sequential processing (Vaswani et al., 2017). This innovation paved the way for models like GPT-3 and GPT-4, which power today’s chatbots and other smart systems.
First Machine Learning, Now Deep Learning
The growth of ML has been driven by the availability of huge amounts of data and more powerful computers. ML algorithms are used in various fields such as recommendation systems on streaming platforms, spam filtering in emails, and even self-driving cars. The field has grown from simple rule-based systems to complex models that can handle diverse and nuanced tasks. As the complexity of real-world problems grew, so did the need for models that could capture deeper, more abstract patterns in data—beyond what traditional ML techniques could handle.
This led to the emergence of Deep Learning (DL), a specialized subset of ML that uses multi-layered neural networks to model complex relationships in large, unstructured datasets. Inspired by the structure and function of the human brain, these models are capable of learning hierarchical features directly from raw data—automatically identifying and refining patterns in images, text, and audio. In essence, DL amplifies the core idea of pattern recognition by enabling systems to solve more complex problems with greater accuracy and minimal manual feature engineering.
The DL revolution took off in the 2000s, largely thanks to two major advances: the rise of massive datasets and the use of GPUs. Originally designed for video games, GPUs are especially good at handling many calculations at once—something DL needs to train large neural networks. With GPUs, researchers could finally process huge amounts of data quickly and efficiently, making it possible to build powerful AI systems. This breakthrough led to major progress in tasks like image recognition, language understanding, and speech recognition. Today, DL powers most advanced technologies—like voice assistants, automatic translation, and even tools that create realistic images and videos from scratch.
All About Large Language Models (LLMs)
Large Language Models (LLMs) are sophisticated AI systems engineered to process, understand, and generate human language with a natural and intuitive fluency. These models are built on Transformers, enabling them to focus on various parts of a sentence or extended text passages. This capability is critical as it allows the models to analyze and interpret language as it would human thought processes, paying attention to specific words and phrases to capture context in dialogue.
The way LLMs generate text, like composing emails or answering questions, is based on a process called autoregression. In this process, the model looks at a sequence of words and predicts the next word in a sequence using probabilities. These probabilities are calculated by training the model on large datasets of text, where it learns to adjust its internal settings to minimize prediction errors, ultimately learning how language flows and functions. The model employs a Transformer architecture with an attention mechanism, allowing it to weigh the importance of each word in a context when making predictions. This learned data then informs the model how likely each possible word is to be the next one in the sequence, enabling it to choose words that make the most sense contextually and syntactically.
Autoregression looks at a sequence of words and predicts the next word in a sequence using probabilities.
This technology manifests in everyday life through various user interactions. Virtual assistants like ChatGPT or Claude answer questions in natural language, email applications suggest how to complete sentences, and customer service tools on websites provide instant support, showcasing just a few ways LLMs are integrated into daily routines. These models also operate behind the scenes, such as in search engines to deliver more relevant results. Increasingly, LLMs are being integrated into search experiences not just to enhance results, but to replace the way traditional search works by now directly generating answers (hence why it is coined “Generative AI”) and providing sources for users. Essentially, LLMs streamline and enhance interactions with technology, making devices and applications more useful and responsive to individual needs. As these models continue to evolve, they are expected to become even more ingrained in daily digital experiences, transforming how people interact with the world.
Conclusion
Artificial Intelligence has evolved from symbolic logic and early neural experiments into a powerful, data-driven technology that now permeates many aspects of daily life. Thanks to breakthroughs in hardware, learning algorithms, and model architectures like transformers, AI systems have become increasingly capable of tasks once thought to require human intelligence. From understanding language to analyzing images and making predictions, the field continues to redefine what machines can do. As society moves forward, understanding this historical and technical foundation is essential for navigating the opportunities and challenges AI presents. What began as a theoretical curiosity has grown into a transformative force shaping our digital future.
Angad Sandhu, MS, is a software development engineer at Amazon, specializing in ML, NLP, and MLLM. As a graduate researcher at Johns Hopkins Medicine, he helped develop multimodal AI systems that integrate video and text data to enhance surgical training.
Vishesh Gupta is a Computer Science and Mathematics undergraduate at the University of Maryland, specializing in NLP and LLM. He is an AI/ML intern at Explore Digits, contributing to the research and development of AI-driven tools and products. His undergraduate thesis focuses on addressing the limitations of LLMs and exploring methods to enhance their performance.
Faizan Wajid, PhD, is a senior data and research scientist at Explore Digits, where he develops AI-driven tools to support healthcare providers, from policy makers to caregivers. His research interests include sensors and signal analysis using wearable technologies, as well as LLM.
Photo credit: Shutterstock/DC Studio
References
Adrian, E. D. (1914). The all-or-none principle in nerve. Journal of Physiology, 47(6), 460-474. doi: 10.1113/jphysiol.1914.sp001637
Agar, J. (2020). What is science for? The Lighthill report on artificial intelligence reinterpreted. The British Journal for the History of Science. 53(3): 289–310. doi:10.1017/S0007087420000230
Alammar, J. (n.d.). The illustrated transformer: Visualizing machine learning one concept at a time. https://jalammar.github.io/illustrated-transformer/
Babar, Z. (2024). Evolution of symbolic ai: From foundational theories to contemporary advances. Medium. https://medium.com/%40zbabar/evolution-of-symbolic-ai-from-foundational-theories-to-contemporary-advances-5ef74b179fa9
Kang, B. (2024). Understanding GPU usage—enhancing high-performance computing. Medium. https://medium.com/%40sangjinn/understanding-gpu-usage-enhancing-high-performance-computing-f03908d13777
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, & K. Q. Weinberger (Eds.), Advances in neural information processing systems 25 (pp. 1097–1105). Curran Associates.
Mayor, A. (2023). The ancient forerunner of AI. Engelsberg ideas. https://engelsbergideas.com/notebook/the-ancient-forerunner-of-ai/
McCulloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics 5, 115–133. https://doi.org/10.1007/BF02478259
Peter, S. (2024). AI was born at a US Summer camp 68 years ago. Here’s why that event still matters today. International Science Council. https://council.science/blog/ai-was-born-at-a-us-summer-camp-68-years-ago-heres-why-that-event-still-matters-today/
Raghuvanshi, S. (2023). The evolution of backpropagation: A revolutionary breakthrough in machine learning. Medium. https://suryansh-raghuvanshi.medium.com/the-evolution-of-backpropagation-a-revolutionary-breakthrough-in-machine-learning-4bcab272239b
Rosenblatt, F. (1958). The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386–408. https://doi.org/10.1037/h0042519
Stryker, C. (n.d.). What is a recurrent neural network (RNN)? IBM. https://www.ibm.com/think/topics/recurrent-neural-networks
Turing, A. M. (1950). Computing machinery and intelligence. Mind, 59(236), 433–460. https://doi.org/10.1093/mind/LIX.236.433
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. & Polosukhin, I. (2017). Attention is all you need. In Proceedings of the 31st conference on neural information processing systems (NIPS 2017), Long Beach, CA.











